Prenorm vs postnorm
2025年9月17日
10:09
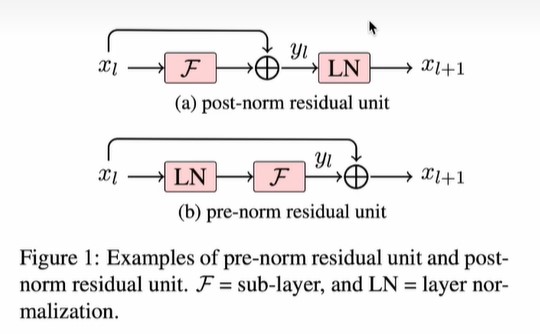
上图中F表示sub-layer,可以是attention层,也可以是ffn层。
postnorm是LN层在残差连接之外 ,而prenorm是LN层在残差连接内部。
为什么主流transformer从postnorm改成了prenorm?因为prenorm训练更加稳定。
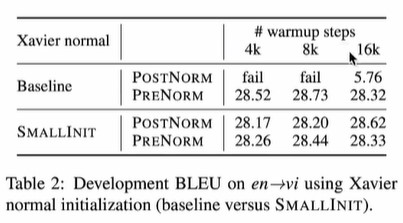
这篇论文,发现prenorm可以不进行warmup,而postnorm需要进行一定的warmup才能收敛,且网络越深需要的warmup步数越多。
为什么postnorm训练不stable呢,需要warmup呢?
微软的论文Deepnet: scaling transformers to 1000 layers:
postnorm将layernorm放在residual connection之外 ,如果不经过合适的warmup 或initiazaiton,会出现梯度消失的现象,导致训练不收敛。
从直觉来解释:
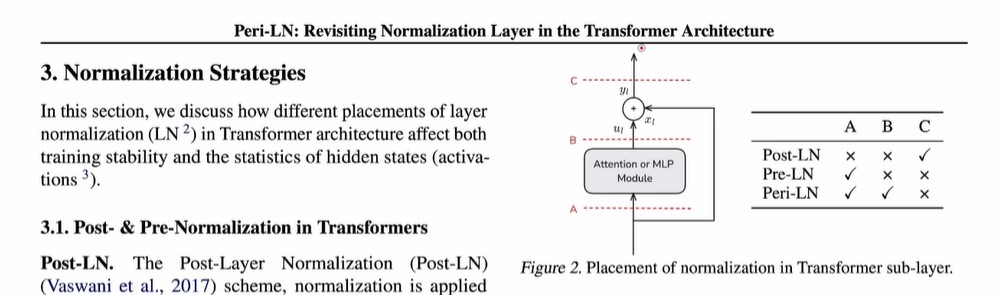
postnorm中layernorm的位置在C,这个位置是信息的唯一通路,此时的layernorm控制了信息的流通,也就可能导致前面模块attention or mlp module出现梯度消失的问题。
prenorm中layernorm的位置是在A,此时前面上一个模块的attention or mlp module的输出除了经过这个layernorm层传递到网络更深层之外,还可以通过旁边的残差连接传递到更深层,即gradient可以通过残差连接往回传,这解决了梯度消失的问题。
peri-LN这篇paper在A和B处都加了layernorm。